
From voice assistants to AI agents automating workflows, artificial intelligence is reshaping industries and driving an exciting amount of innovation across every sector. But behind the scenes of every AI-powered breakthrough is a sophisticated infrastructure rapidly rising to meet the computational demands.
In this first part of a multi-part series on AI Infrastructure, I want to delve into the requirements of AI systems and the unique challenges that are being solved by IaaS vendors and datacenters all over the world.
Why Infrastructure Matters for AI
A lay take on the Infrastructure as a Service (Iaas) and cloud computing industries would probably focus on the idea of “More”. More speed is driven by more servers with cpu’s, more ram, more bandwidth and more datacenters in more regions. More data storage is needed so we need more hard drives, more SANs, and more offsite backups. We need more power and more cooling so we better start ramping up more power plants.
While scaling will generally be part of the solution to the skyrocketing demands on IT teams and datacenters, the needs of AI Infrastructure are far more complex. For example, a billion CPUs may not be able to compete with a handful of application specific integrated circuit (ASIC) processors fit for the given task.
Another layer of complexity is added when you account for the entire AI Lifecycle:

During the early lifecycle of an AI model huge demand is placed on compute resources to process data and train. Once a model is trained and published to users, however, the focus shifts to obtaining lightning fast responses from the model and returning those results to users quickly and consistently. The majority of your infrastructure needs need to account for the high utilization demands of model training while also accounting for the inference period when you need extremely low latency.
AI Compute Requirements
Computational Patterns
AI training is essential a matrix multiplication operation.In order to meet the massive parallel processing capabilities driven by the fundamental nature of these tasks systems must support synchronized computation across distributed systems with heavy emphasis on floating-point operations that have specific precision requirements.
Let’s start talking about compuute requirements by breaking down what’s actually happening during training. When a neural network processes data, it’s performing millions or even billions of matrix multiplications. (See here for a reminder on how neural networks are represented with matrices.) Each layer of the network transforms its input data through these operations, applying weights and biases before passing the results to the next layer. This process happens for every piece of training data, and then happens again in reverse during backpropagation when the model is learning from its mistakes.
This computational pattern has several important implications for infrastructure:
Parallel Processing
The nature of matrix multiplication means these calculations can be done in parallel. Modern AI infrastructure takes advantage of this through specialized hardware like GPUs and TPUs that can perform thousands of calculations simultaneously. But it’s not enough to just have parallel processing capability within a single device – large models often need to distribute these calculations across multiple devices or even multiple machines.
Think about training a large language model (LLM). The model might be too big to fit on a single GPU, so you need to split it across multiple devices. Now you need infrastructure that can coordinate these devices, ensuring they stay synchronized as they process different parts of the model. This is where technologies like NVIDIA’s NVLink or high-speed interconnects become crucial.
Precision Requirements
Not all numbers are created equal in AI computations. Different types of neural networks and different stages of training may require different levels of numerical precision. Some operations need 32-bit floating-point precision for accuracy, while others can use 16-bit or even 8-bit precision to save memory and increase speed. Your infrastructure needs to support these various precision requirements while ensuring the results remain mathematically stable.
Memory Bandwidth
Matrix multiplication isn’t just computationally intensive – it requires moving large amounts of data between memory and processing units. In fact, many AI workloads are actually memory-bandwidth bound rather than compute-bound. Your infrastructure needs to provide not just raw computational power, but efficient memory systems that can keep those compute resources fed with data.
Transitioning to Inference
Once a model is trained, the computational patterns change dramatically. During inference (when the model is actually being used), the focus shifts from raw computational power to low latency and consistent performance. You’re typically processing one request at a time and need to return results quickly.
This creates an interesting infrastructure challenge: how do you build systems that can efficiently handle both training and inference workloads? Some organizations solve this by having separate infrastructure for each purpose. Others use adaptive systems that can be reconfigured based on current needs.
Consistent Results
Inference latency isn’t just about raw speed – it’s about consistency. Users expect AI systems to respond quickly every time, not just on average. This means your infrastructure needs to minimize not just average latency but also the variance in response times. This often requires careful attention to:
- Queue management for incoming requests
- Load balancing across inference servers
- Cache optimization for frequently requested operations
- Resource isolation to prevent interference between different workloads
The computational patterns in AI workloads continue to evolve as new model architectures and training techniques emerge. Staying ahead of these changes requires infrastructure that’s not just powerful, but flexible enough to adapt to new patterns as they arise. Understanding these fundamental patterns helps architects make better decisions about how to design and optimize their AI infrastructure.
Data Management
Infrastructure must support extremely high throughput for the large scale parallel processing systems to consume training data. When we say AI training data is “massive,” we’re often talking about petabytes. Imagine trying to process every frame from millions of hours of video, or every word from billions of documents. Not only do you need somewhere to store all this data, but you need to be able to move it efficiently to where it’s needed. Traditional datacenter storage systems that might work fine for regular applications often buckle under these demands. And, this data typically requires pre-processing, so the system will need to support complex pipelines.
Caching becomes critically important at this scale. Smart caching strategies can dramatically reduce the load on your storage systems and improve training performance. But implementing effective caching for AI workloads isn’t simple – you need to consider:
- What data is most likely to be needed again soon
- How much cache space different training jobs need
- When to invalidate cached data
- How to maintain cache coherency across distributed systems
Storage architecture becomes particularly crucial when you’re operating at AI scale. Many organizations end up implementing tiered storage systems that have high-speed local storage for active training data, network-attached storage for datasets that need to be regularly accessed, and then archive storage for longer-term data retention options. Each of these may be structured or unstructred depending on the use case.
The key to successful data management for AI is building infrastructure that can handle not just today’s data volumes, but tomorrow’s as well. As models become more sophisticated and training datasets grow larger, your data management infrastructure needs to scale accordingly. This often means designing systems that can easily expand both horizontally (adding more storage nodes) and vertically (upgrading to faster storage technologies).
Peak Resource Utilization
During the training phase, AI infrastructure will need to handle sustained high utilization for weeks or months and not suffer perforamnce degradation even during the training of larger models. This consistency require robust power management, fault tolerance to avoid the loss of training progress, and a memory bandwidth that can handle the constant parameter updates that are happening during training.
The greater challenge, however, is that there are far more modest needs during inference. Smaller organizations can leverage Pay-As-You-Go and short term IaaS services while training, but will pay a significant premium over larger organizations that can schedule training or find other opportunities to use the computing resources when they are actively training. There are different optimization strategies between the two faces and the infrastructure strategy has to be flexible enough to accommodate it.
Development and Iteration
Think about how data scientists actually work. They’re constantly tweaking parameters, trying different model architectures, and testing various approaches to see what performs best. Infrastructure needs to support this rapid experimentation without getting in the way. This means having systems that can quickly spin up training environments, manage different versions of models, and track all the experiments being run.
Development infrastructure needs to support several key capabilities:
- Experiment Management: Systems to track different model versions, hyperparameters, and training runs. This includes storing model artifacts, training logs, and performance metrics for each experiment.
- Rapid Prototyping: The ability to quickly test new ideas with minimal overhead. This includes easy access to development environments and training resources.
- Version Control: Not just for code, but for models, data, and configurations. Teams need to track what version of each component was used for any given experiment.
- Automated Testing: Infrastructure to automatically validate models against benchmarks and test sets, including checks for accuracy, performance, and resource utilization.
- A/B Testing Framework: Systems to deploy multiple versions of models simultaneously and route traffic between them intelligently, collecting performance metrics for comparison.
A/B testing becomes particularly crucial once you’re closer to production. Developers might want to test different versions of the model with actual users to see which performs better in the real world. This requires infrastructure that can simultaneously serve multiple versions of the model, route traffic between them intelligently, and collect detailed performance metrics for comparison.
Other Considerations
Cybersecurity
When we talk about security for traditional IT systems, we usually think about firewalls, access controls, and protecting sensitive data. But AI infrastructure security introduces a whole new set of challenges that many organizations are just beginning to understand.
Think about what happens during model training. You’re not just protecting static data – you’re protecting an active learning process that could be subtly manipulated by bad actors. These “adversarial attacks” might sound like science fiction, but they’re a real concern. An attacker could theoretically introduce carefully crafted data that causes your model to learn the wrong patterns, leading to unexpected behavior when it’s deployed.
This creates an interesting challenge for architects. They need to build environments that are both extremely secure and highly accessible to data scientists and researchers. It’s not enough to just lock everything down – teams need to actively work with the data and models throughout the development process.
The complexity doesn’t stop once a model is trained. In production, you need to protect not just the model itself, but also all the data flowing in and out. Infrastructure teams need to implement encryption schemes that don’t slow down model performance – users expect AI systems to respond quickly, and security measures can’t get in the way of that.
Compliance and Governance
The infrastructure must support comprehensive model lineage tracking and maintain audit trails of training data and parameters. Systems for tracking and managing model versions in production are essential and they need to be adaptable to the ever-increasing comliance requirements. This is more important for AI models specific to certain industries like Healthcare, Banking, and Manufacturing but all developers have to think carefully about rules around the data used in training their models, the edge cases which might step into areas requiring strict regulatory compliance, and the resulting requirements for their infrastructure.
Scalability Patterns
Scaling AI infrastructure isn’t as simple as adding more servers when things get slow. You need to think about scaling in multiple dimensions, and each approach has its own sweet spot.
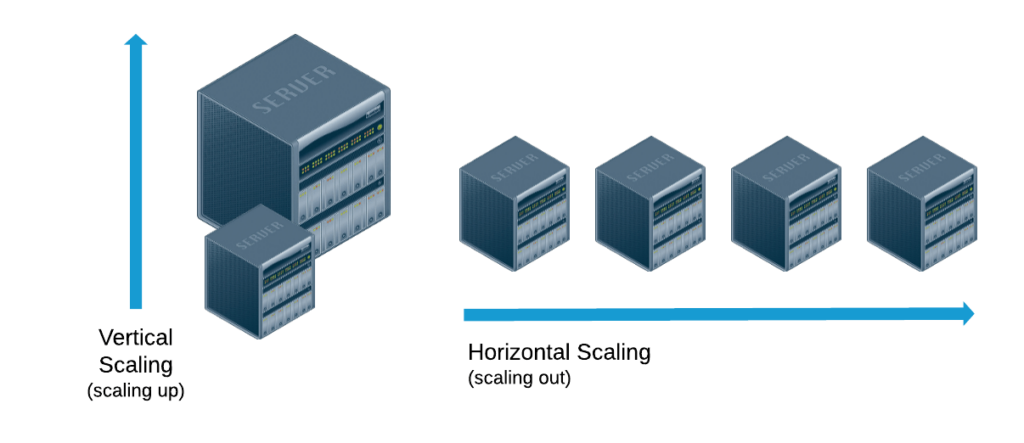
Vertical scaling – adding more resources to your existing machines – seems simple at first. Need more power? Add more GPUs or memory. But there’s a catch. You can only add so much to a single machine before you hit physical limits or the costs become astronomical. Still, for some AI workloads, especially training larger models, this might be your only choice.
Horizontal scaling – spreading your workload across more machines – often looks more attractive on paper. It’s usually more cost-effective, and it gives you more flexibility. You can add or remove machines as needed, perfect for handling multiple training jobs or serving lots of inference requests. But now you’re dealing with the complexity of orchestrating all these machines to work together smoothly.
The real magic happens when you figure out how to automatically scale these resources up and down based on what’s happening in your system. Maybe you need more machines when your training queue gets too long, or when too many users are requesting responses at once. But you don’t want to keep these resources around when you don’t need them – that’s just burning money. Finding this balance is where many organizations spend a lot of their time and energy.
Infrastructure Redundancy
Having backup systems ready to take over isn’t just good practice anymore – it’s an essential requirement. But it’s not enough to just have spare machines sitting around. You need systems that can seamlessly pick up where others left off. This is especially crucial for training jobs that might run for weeks. Imagine losing days of training progress because a single machine failed!
Storage redundancy gets even more interesting with AI workloads. You’re not just backing up data – you’re protecting training datasets that might have taken months to compile, model checkpoints that represent weeks of training progress, and the actual models themselves. Each of these needs its own backup strategy, and you need to be able to recover any of them quickly when needed.
Your network needs multiple paths between all these components too. It’s like having multiple routes to work – if one road is blocked, you need alternatives. This becomes even more important when you’re running AI systems across different geographic locations.
Performance Benchmarking
Measuring the performance of AI infrastructure is a bit like trying to judge a decathlon – there are many different events to consider, and excellence in one area doesn’t guarantee overall success.

For training workloads, you’re looking at how quickly you can complete training runs, how efficiently you’re using your expensive GPU resources, and whether you’re getting the most out of your memory and storage systems. But raw speed isn’t everything – consistency matters too. A system that’s blazing fast but occasionally hits unexpected slowdowns can be worse than a slightly slower but more predictable one.
When it comes to inference, it’s all about response time and throughput. How many predictions can you serve per second? How long do users have to wait for responses? Are these numbers consistent, or do they vary wildly under load? These aren’t just technical metrics – they directly impact user experience and, often, business success.
The key is developing a comprehensive testing approach that looks at all these aspects. You need to test with synthetic workloads that push your systems to their limits, but also with realistic workloads that mirror what you’ll see in production. And you need to do this consistently over time to catch performance regressions early.
Integration Considerations
AI infrastructure doesn’t exist in a vacuum – it needs to play nice with all your other systems. This is where many organizations face their biggest challenges.
Your data pipelines are particularly critical. AI systems need clean, properly formatted data, and lots of it. Your infrastructure needs to support robust ETL processes, handle real-time data streams when needed, and maintain data quality throughout. It’s not just about moving data around – it’s about ensuring that data is always in the right format, in the right place, at the right time.
APIs become your glue layer, connecting everything together. Whether you’re using REST for simple integration or gRPC for high-performance needs, your infrastructure needs to support these interfaces while maintaining security and performance. Many organizations are finding that service mesh architectures help manage this complexity, providing consistent ways to handle service discovery, load balancing, and security.
Then there’s the whole ecosystem of ML platforms and tools. Your infrastructure needs to support popular frameworks like TensorFlow or PyTorch, integrate with model serving platforms, and work with whatever experiment tracking systems your data scientists prefer. And all of this needs to fit into your CI/CD pipelines so you can maintain a smooth path from development to production.
Environmental Impact
AI infrastructure must be designed with efficient power usage optimization in mind, including robust cooling infrastructure to manage heat generation. Companies that are carbon-neutral or are focused on the environmental affect of their systems will need to consider how new AI infrastructure is going to affect their environmental goals. This may require implementing energy-efficient solutions without compromising computational capabilities.
Meeting AI Requirements
As AI continues to reshape industries, the infrastructure supporting these systems will have to evolve just as rapidly. IT Departments, Datacenters, and large AI vendors like Microsoft and Anthropic face complex decisions around balancing computational needs and using every opportunity to manage resources efficiently. The requirements outlined here represent just the foundation of what’s needed to support modern AI systems.
In the next part of this series, we’ll explore the specific infrastructure (e.g. CPU/GPU/ASIC, SANs, Monitoring Tools, etc.) organizations are use to meet these challenges, and examine some of the innovative solutions being developed to address unique demands of AI workloads.
IT leaders and architects should carefully evaluate their current infrastructure against these core requirements. The success of AI initiatives depends not just on the models themselves, but on building a robust foundation that can support both development and production environments effectively.
{kind=link}